
扫码关注昆仑芯科技公众号
分享|昆仑芯×飞桨:适配方案大揭秘
芯见闻 发布于 2022-11-01 18:30
10月24日,来自飞桨与昆仑芯科技的两位专家带来了一场精彩的线上直播,对昆仑芯与飞桨III级适配方案进行深度解读。
本篇以下内容整理于昆仑芯×飞桨系列直播第二期——昆仑芯科技资深架构师侯珏、飞桨训练芯片适配技术负责人李琦题为《昆仑芯×飞桨:适配方案大揭秘》直播分享。

昆仑芯科技资深架构师 侯珏
很高兴能有这个机会和大家进行分享和交流,今天和大家分享的题目是《昆仑芯和飞桨的适配方案大揭秘》。
首先解释一下“适配”。这里的“适配”不仅仅是“凑合能跑”,不是千挑万选、好不容易跑通一个模型就敢喊适配的情况,而是达到了飞桨认证的最高等级的III级适配——昆仑芯的RD提测,飞桨的QA同学一个个模型训过去、测过去,结果符合预期,并且已有稳定流水线在跑的那种适配。
简而言之,就是昆仑芯设备和飞桨框架本身,以及周边的一大堆套件都可以很好地一起工作。什么叫“很好地一起工作”?或者说昆仑芯的硬件设备,与大家熟悉、习惯使用的各种传统GPU设备有什么不同?
首先可以看一下这个视频,其实就是个录屏,没有剪辑拼接的内容。这是一个典型的飞桨demo,是mnist数据集和简单的小网络,默认用CPU进行模型训练。
在用户的代码中,声明使用了CPU设备。那么后续的模型训练的各种算子,包括前向和反向,就会都跑到CPU设备上去。这应该是大家平时最熟悉,也最常用的使用方法。
右边是开了一个watch进程,执行这个xpu_smi。简单介绍一下,这里的xpu_smi对应GPU上的nvidia-smi,也是用来展示硬件设备信息的。比如设备号、状态、使用率、内存使用率、进程号、进程名等。
可以看到,一开始昆仑芯AI加速卡的设备利用率是0,也就是没跑上去。这是对的,因为一开始就是跑在CPU上。下一步我们改了一行代码,准确地说是改动了一个字母:把CPU的C改成XPU的X,就可以把CPU Device换成XPU Device,整个训练过程就全都跑到我们的昆仑芯设备上了。在右边的监控上也就能看到使用率。
就是这么简单,和大家平时跑模型训练,把CPU的C换成GPU的G,就能切换到GPU上,是一个意思。
所以通常情况下,大家在昆仑芯XPU的环境下,把历史能跑通的各种代码里的GPU的G都给换成XPU的X,也能跑起来。
以上是一个单机单卡的简单的例子。如果大家使用过飞桨的fleet组件来跑分布式的话,其实也是可以“一个字母”搞定设备切换的。开场视频中放的是个demo例子。可能大家会觉得,这个东西只能玩玩而已,正式的模型,或者是生产环境是不是也能这么简单搞定?
这里放了一个真实例子的代码,是我正在做的某个项目的真实的代码。能看的出来,这个图显然是拿vim打开后截图出来的,连行号都在。图中的代码,写的是fleet的初始化部分,首先是一个fleet的init,然后来一个分布式模型的config,并且刷config的各种属性,比如模型路径、各种rank号、各种id。刷好之后,在尾巴的第63行的这个地方,拿config去创建一个分布式模型DistModel。
我就改了一行代码,即红框内的部分,把原来config的place,由原来的GPU改成了昆仑芯XPU。整个后边的所有逻辑就从GPU设备全跑到昆仑芯AI加速卡上面去了。
以上提到的都是,“自己写代码,要怎么修改device类型以达到切换设备的目的”。如果使用飞桨的套件,那就更简单,甚至不用动python脚本文件,直接改启动训练的命令行,改入口的shell脚本即可。就目前的支持程度而言,在飞桨的多个套件中,均有针对昆仑芯设备的配置项的特殊处理。
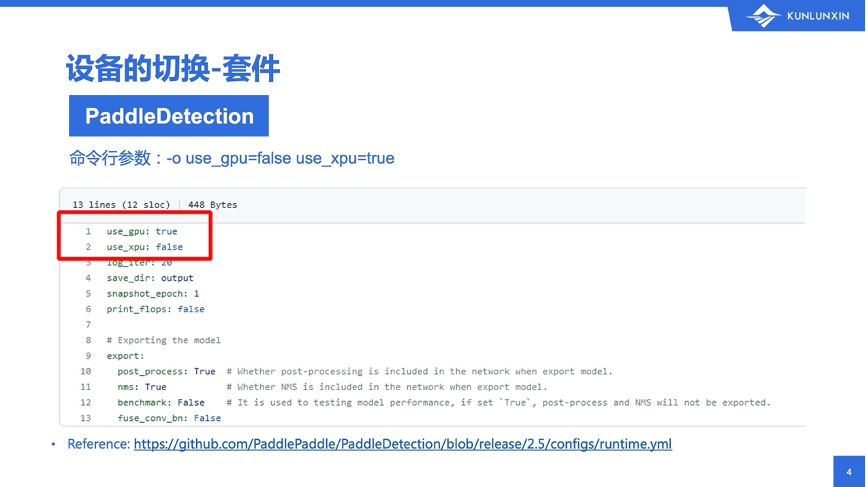
比如这个例子,这是飞桨的目标检测套件,PaddleDetection。用过的朋友可能都知道,PaddleDetection的configs目录下面,有30多个子目录,每个子目录放了一大堆常见的模型配置,比如说网络结构、预训练模型的地址等。
在configs目录顶层,有一个runtime.yml。这个文件比较小,一共只有13行,如图所示,我就把release/2.5这个最新的稳定分支的内容全贴过来了。图上有一个链接,方便大家回顾和验证。
正因为yaml文件在configs目录的顶层,文件内容又很小,里边也没什么干货,所以平常没什么人注意到这个东西。但由于大家使用的、真正用来模型训练的yaml都会首先依赖这个runtime.yml。这导致你使用什么设备,都是这个runtime.yml说了算,而跟具体什么模型、网络结构都没关系。
所以,如果你想跑的模型在我们给出的支持列表中,那么你只需要改一下启动的命令行,把默认的use_gpu的true改成false,然后把use_xpu打开就搞定了。还有一种更偷懒的办法:直接改yml文件,让它默认跑到XPU上,就不用一个个改模型的启动命令行了,改一个地方就全搞定。
以上部分就是所有的前言部分。有句话叫“哪有什么岁月静好,只不过是有人替你负重前行”。这句话放在深度学习框架或者平台上也有道理。意思是没有一个功能是天然实现的。如果大家觉得这个东西用起来很方便、很舒服,那肯定是有人没那么方便、没那么舒服,给大家一行一行写出来,然后拿出来用的。
所以,接下来我将给大家进行一系列的拆分和讲解,揭秘昆仑芯和飞桨的背后故事,总共分为四部分:
模型训练
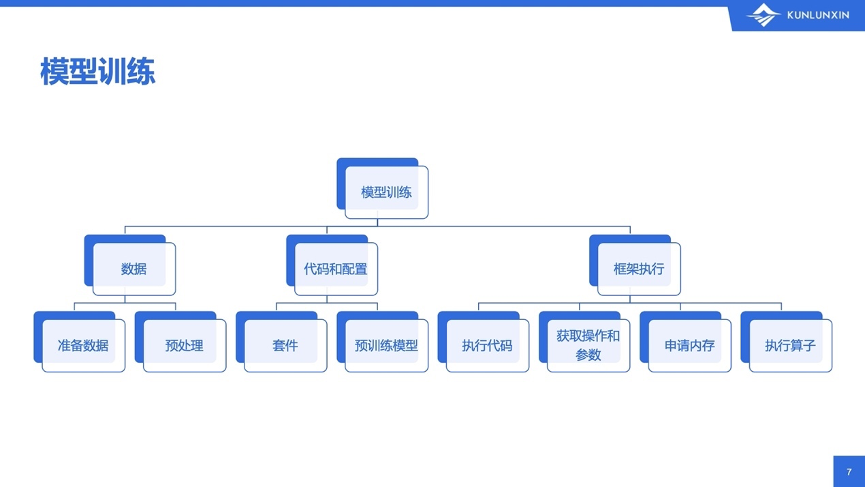
一个典型的模型训练有三个组成部分:数据、代码、框架执行。
飞桨的组成部分可以再把它往细了拆:
使用者关注的重点主要在前面两部分,也就是用什么样的数据,如何进行预处理,使用什么样的网络结构。但是,从飞桨和昆仑芯的开发人员的角度来说,关注的重点在最后部分,即,如何使用我们的昆仑芯来执行用户指定的操作。那么,可以进一步拆解,框架要做的事情有这些:执行用户的代码,知道有哪些操作,有哪些参数,参数都是什么形状。然后在设备上申请适当的内存(也叫显存或device memory),最后在设备上调用设备支持的算子以进行真正的计算。
三个组成部分

一方面,从飞桨角度,增加昆仑芯设备的适配,从粗粒度的概念来说,重点是以下三个:
第一,新来的设备必须能支持内存分配,并且能从CPU(也就是host)把数据拷过去。拷过去的数据算完了还得能拷回来,也就是需要支持device和host之间的双向拷贝。在多设备的情况下,还有一些特殊的拷贝,比如单机多卡或者多机多卡时,不能只有CPU跟device拷贝,device和device之间也得能互相拷贝。
第二,有足够的算子支持。比如给了两个矩阵要做乘法操作,通常的方法是输入两个内存的指针,输出再来个指针,再给个矩阵形状,包括矩阵的m、n、k。给了这些之后,得能在设备上进行乘法操作,算完了再写回到输出指针指向的空间上。
第三,分布式。就是在分布式环境下,能够在多个设备上进行通信和计算。比如broadcast分发、allreduce合并等。再细致一些的话,allreduce还得支持多种类型的合并,reduce_sum求和、reduce_min取最小等都要支持。
另一方面,从昆仑芯的角度,即芯片设计角度来看,设计之初就没有要强绑定某个特定的框架,正如飞桨可以使用多种类型的异构计算设备。
昆仑芯对于PaddlePaddle框架,从对外的产出和接口而言,或者说和飞桨适配最相关的部分,有三个。这三个部分也是飞桨在编译时,所依赖的xpu.cmake文件中,指向的三个文件。每个文件是一个压缩包,包括所需要的头文件.h和预编译库的.so。

第一,runtime:运行时环境,包括驱动、管理工具。基础的内存分配、释放操作等都在里面。
第二,xdnn:神经网络高性能加速库,也叫算子库。主要包括大量在dnn里需要的操作:乘法、卷积、池化、激活等。
第三,xccl:集合通信库,用来进行单机多卡以及多机多卡之间的通信。
当大家打开XPU模式,也就是在cmake的命令行里追加一个-DWITH_XPU=ON,并且编译PaddlePaddle之后,就会在编译目录的third_party/install/xpu目录下看到各种头文件和动态链接库。
我介绍的部分都是已经完成的工作,大家也都是开发者的身份,那么借用一句大家都熟悉的Linus大神的话,“Talk is cheap. Show me the code.”,能贴代码的地方,我就尽量给大家直接贴代码,比较直观清晰。
下面是三个组成部分的细节。
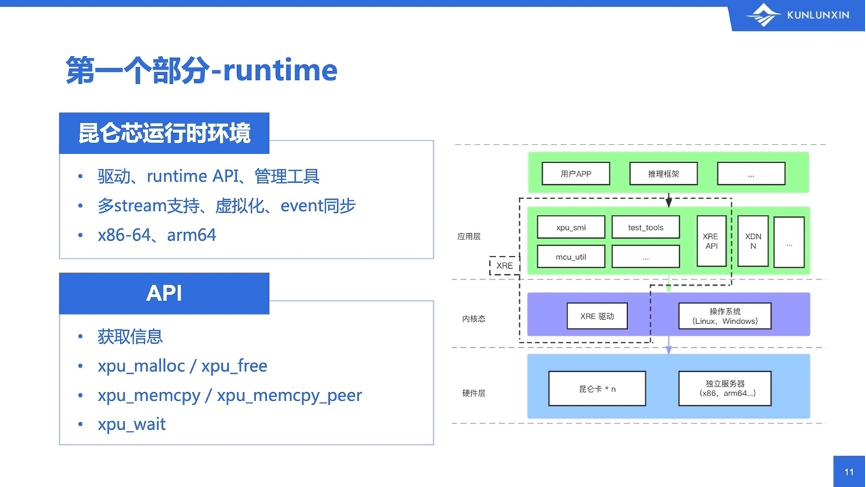
第一部分,runtime,也叫做昆仑芯的运行时环境。它包括了驱动、API以及一系列管理工具。比如开场视频中观察昆仑芯芯片状态的工具xpu_smi,也是在runtime内的。
runtime支持多stream、虚拟化、event同步等,并且有多个发布版本,可以支持x86和ARM平台。不过对于飞桨框架来说,大家可见的runtime,主要是API部分,也就是一个叫runtime.h的头文件。runtime.h,首先包括了一些“获取信息”的函数,比如获取驱动版本号、当前系统中昆仑芯XPU设备的个数等。然后是在当前工作设备上分配和释放内存的xpu_malloc和xpu_free。
其次,在昆仑芯XPU和CPU之间要能进行拷贝,所以有xpu_memcpy、在不同昆仑芯XPU设备上进行拷贝的xpu_memcpy_peer。最后,就是等待一个计算流,也就是stream上等待所有函数执行完成的xpu_wait。
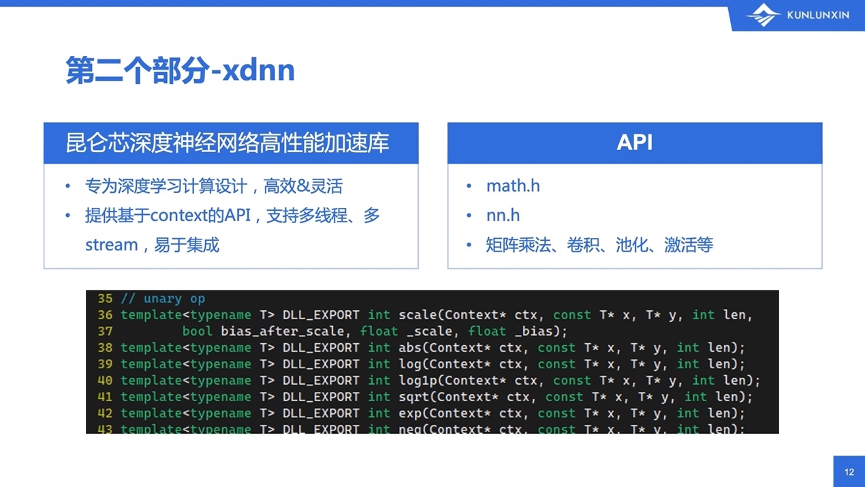
第二部分是xdnn。从整体上来说,xdnn是专门为深度学习计算进行设计和开发的算子库。从使用方法上来说,它提供了基于context的API,支持多线程、多stream,易于集成,并不强绑定某个特定类型的框架。
里面的算子经过长时间的打磨和迭代,主要是增加数量以及优化已有的算子。直到现在,整体处于一个相当稳定,并且高效灵活的状态。
根据功能的不同,xdnn把算子拆到不同的头文件里,方便大家使用和查找。例如math.h,一看名字就知道是“纯数学相关”的;而nn.h则是“神经网络相关”的。
找一些相对简单的函数来举例,math.h中有很多一元函数,比如scale、abs、log等。函数的输入输出都长得差不多,给一个上下文环境、输入指针、输出指针、长度、模板类型T,就可以开始算了。这个函数的功能也很简单,就是把数据输入,算一下再输出。原样进来,然后写到等长的空间里。
所以,从实现上来说,XPU的API和其它的异构计算设备的API还是比较接近的。调用方法也很接近,都是在CPU上发起一个操作,然后在我们的device上执行。
需要说明的一点是,在某些xdnn算子的内部实现中,会根据用户的输入数据的形状进行智能选择,对数据进行合理的切分和计算。
第二个要说明的是,在一次xdnn的API调用中,可能包含若干次kernel的启动和执行,也可能使用好几个不同功能的kernel,从而完成一个较为复杂的算子的计算。
不过,这些对于飞桨以及其它外部框架都是透明的。调用者只需关注API的输入输出参数以及返回值即可,不用管内部kernel的种类、调用次数、如何launch等细节。
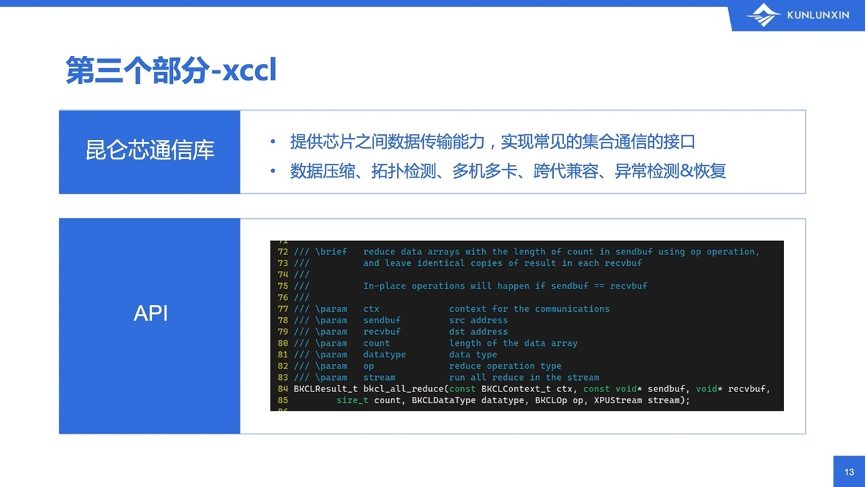
第三部分xccl,是昆仑芯的通信库,它提供了芯片之间数据传输的能力,实现了常见的集合通信的接口,比如一开始提到的bkcl_broadcast、bkcl_all_reduce。这里的BKCL,就是百度-昆仑-Communication-Library。
用bkcl_all_reduce的API作为例子。参数有以下几个:上下文、发送和接收的缓冲区(一个叫sendbuff,一个叫recvbuff)、数据类型和元素个数、使用哪个流,以及allreduce需要支持多种类型的reduce方式,比如add求和、product求乘积,min求最小值、max求最大值等。以上就是bkcl_all_reduce函数的原型,大家需要用的话,直接把数据准备好,调一下这个API即可。
和之前提过的xdnn的API相比,用户也无需关心内部的实现和kernel launch,只需要准备好数据,调用API,拿返回值即可。
以上介绍了模型系列的三个组成部分,下面请飞桨训练芯片适配技术负责人李琦为大家进行介绍昆仑芯与飞桨适配的技术细节。
飞桨框架如何与昆仑芯软件栈一起工作

飞桨训练芯片适配技术负责人李琦
大家好,我是李琦,来自飞桨研发团队。刚才,昆仑芯科技资深架构师侯珏非常详细地介绍了昆仑芯技术软件栈的架构,我就给大家讲一讲飞桨框架是如何与这套昆仑芯的软件栈一起工作,将飞桨的模型运行在昆仑芯上。
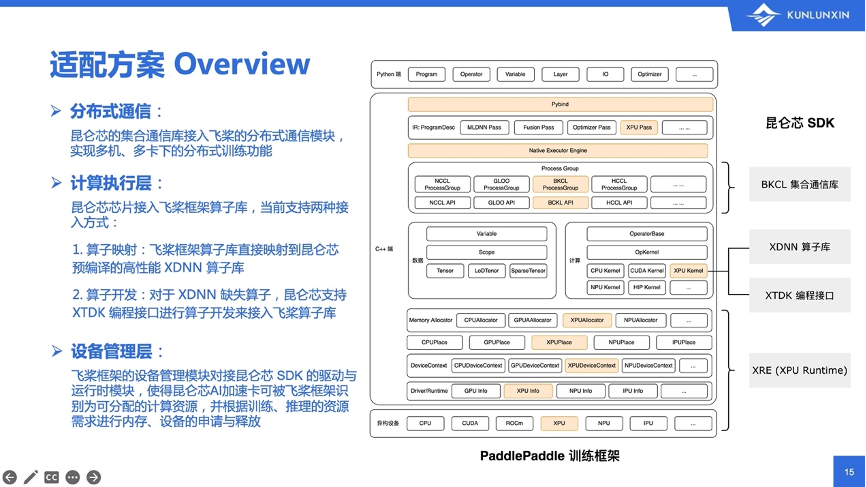
上图右侧是飞桨框架的一个架构图。从上往下,可以分成Python接口层、C++层和底部的硬件层。中间的C++层,涉及了很多飞桨框架内部的底层概念,包括模型的IR表达、算子和张量的IR表达、框架的执行器、分布式的通信模块,以及飞桨框架的内存管理模块和设备管理模块等。
昆仑芯软件栈和飞桨框架的适配主要分成三个部分,从下往上分别有:
通过这三个主要功能模块的适配,就可以成功将飞桨模型的训练、推理任务运行在昆仑芯芯片上。
下面再交给侯珏来给大家详细解读一下我们适配代码。
昆仑芯科技资深架构师 侯珏
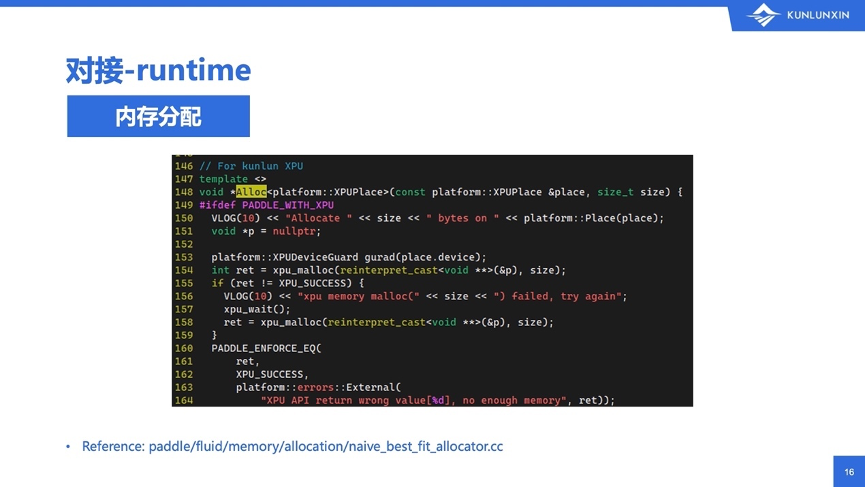
对比一下可以发现,以上三个昆仑芯的依赖,正好对应了飞桨提出的三个需要:运行时、算子库、通讯库。还差什么?还差的是怎么把昆仑芯和飞桨对接在一起。
首先来看第一部分,runtime的对接。runtime是内存的分配,跟其它类型的硬件设备的内存分配和回收方式差不多,都是一个叫Alloc的函数,给一个设备,再给一个长度,返回一个void*类型的指针。实践上也很简单。直接调用xpu_malloc函数,尝试分配内存。如果分配失败了,中间会调一次同步,然后再重试。具体的代码图中有给出reference,在memory/allocation目录下面,大家可以去看看它的分配,也可以去对比一下跟其它设备分配有什么样的不同。
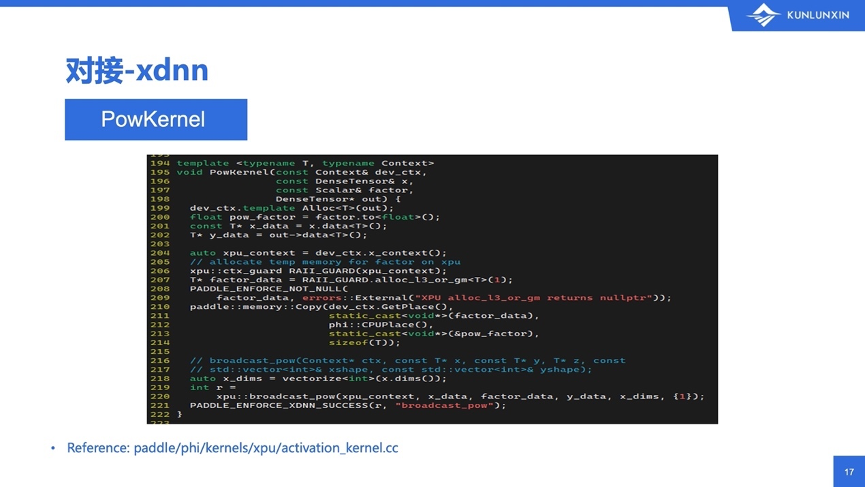
第二部分是xdnn的对接。最近飞桨框架有一次较大的升级,把整体的算子都从原先的fluid下面的operator下面,迁移出来到了phi的算子库里。对于昆仑芯来说,在算子实现的时候,目的都是实现phi里算子的kernel函数,在算子调用时转换到自己设备上实际执行的API调用即可。
图中是一个phi算子的例子,看看怎么从昆仑芯XPU提供的API,变成一个phi的无状态的函数。这里需要提到一个比较简单的激活函数,pow,即计算一个数的多少次方。
计算一个数的多少次方,为什么写出这么多代码来?我们先看一下xdnn底层提供的函数原型,即216行的函数注释,发现这个名字叫broadcast_pow,这个底层自带形状广播。
此外,需要的factor_data,即pow函数的指数,它需要是已经在昆仑芯设备上的指针。所以在算子绑定期间,得临时申请一个大小为1的空间,并且把函数原型输入的factor拷贝到昆仑芯XPU设备上,再调用真正的计算函数。
所以整体上来说,给飞桨框架增加一个昆仑芯XPU算子的支持,本质是在给定的输入和输出下计算出正确的结果。但在具体过程中,有的算子得开临时空间,有的算子需要组合调用多个底层的xdnn的API,有些算子还需要进行一堆参数的转换,比如参数的顺序、含义,跟底层可能不能很好的匹配,需要调整。总之,要根据实际的算子以及底层API的情况具体处理,把这两部分对接起来。
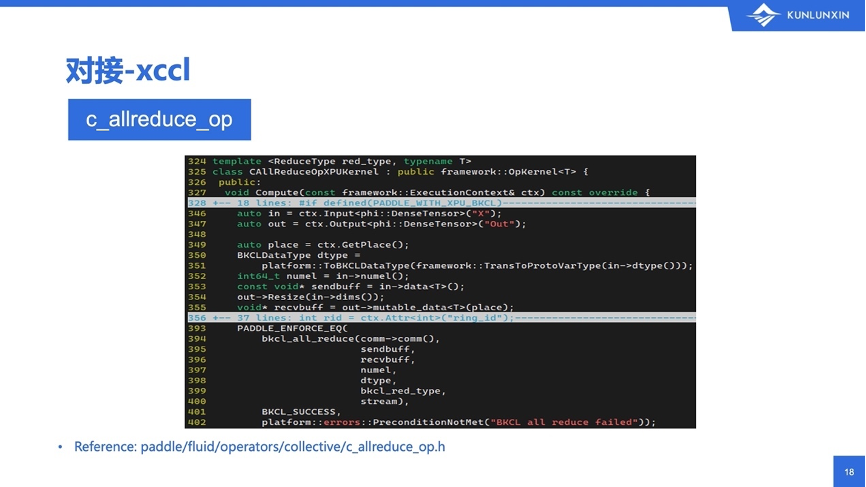
第三部分,看这个xccl的对接。通信相关功能,在PaddlePaddle中也是以算子的形式出现的,所以和上述的xdnn算子的对接方法区别不大。例如,集合通信里有一个带collective的allreduce的op,这里列出了一个头文件叫做c_allreduce_op.h。这个头文件里同时出现了多种设备的实现,看起来互相之间都挺接近,nccl的allreduce调用,也在这个头文件里。
以昆仑芯上的all_reduce操作为例,和上一节提到的和xdnn算子的对接很类似,这里也是:从context里拿到输入跟输出,为了匹配通信库自身的allreduce参数,需要计算收发的大小,以及把Tensor的data指针当作收发的缓冲区。此外还要指定具体在reduce的时候进行的操作,例如前面提到的底层API支持求和、求最小值、求最大值等。
至此,昆仑芯对接飞桨的所有基本操作就讲得差不多了,模型也基本上能跑起来了。不过要想达到更好的适配效果,仅仅是“跑起来不挂”,光靠基本算子的实现和对接也不太够。针对一些特定场景的模型训练、模型推理,GPU上是有一些特殊优化的。比如算子的fusion,把一堆小的算子合并成一个大的算子。优点是什么?优点是一次函数调用,或者一次kernel的launch,就能完成更多更复杂的一系列运算,比反复调用很多次小算子,能减少很多不必要的开销。
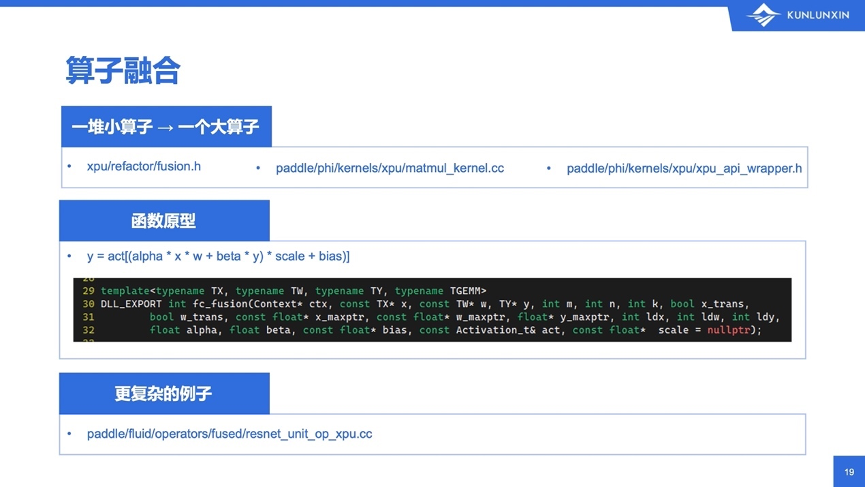
显然,在昆仑芯XPU上也有算子的fusion支持。先举一个简单易懂的例子:fc_fusion,在fc的基础上,追加了bias、scale和激活。
首先看这个函数原型,这个公式,它算的是两个矩阵相乘后,再乘以scale,并且加bias,加完bias再激活。这里的各种操作都是带广播的:alpha和beta的乘法是broadcast_mul,x和w的相乘是普通的矩阵乘法,乘以scale也是broadcast_mul,加bias是broadcast_add,最后再来一个act是激活函数。
其中有一些参数可能是比较常见的,比如输入输出指针、表示矩阵形状的m、n、k,表示输入带不带转置的两个trans、表示两行之间偏移量的offset的leading dimension,还有参数alpha、beta等。这些参数在其它的矩阵计算库里也有,没什么特殊性。
第三个模板函数中有个TGEMM,以及里面三个maxptr:分别对输入x和w,还有输出y,各有一个maxptr,两个是const,一个不是const,这些函数大家可能会觉得很陌生、很疑惑。
给大家简单解释一下,由于昆仑芯设备内部的一些特点,我们设计了这样的参数。在昆仑芯设备的内部,是用量化之后的数据来进行计算的,所以需要一个量化的类型。既然是量化,还得找输入数据的绝对值的最大值,计算一下所有数据跟这个最大值的比例,再“拉”成整数类型。
所以从函数设计上来说,对于普通的计算,这几个maxptr可以全都传空指针,API内部就会自行去找最大值然后量化。但是,针对某些特殊场景,比如预测,就可以先把矩阵乘法里的权重,就是那个w的最大值提前找好存下来,真正计算时就不用每次让API找。你传一个空,API就自己去找,你传一个不空,API就直接从你传的maxptr里读取。
所以,在飞桨上调用昆仑芯的fc时,调的就是fc_fusion。图中列了matmul_kernel的实现,以及外面还垫了一层参数转换用的wrapper。代码比较长,大家可以自己在官网上看看,我们如何把飞桨输入的矩阵,对应到xdnn的fc的API上。
这是一个很直观的例子。当然,也有一些传统意义上的“很多操作聚合在一起的算子”,比如,paddle/fluid/operators/fused/目录下面,有一个resnet_unit_op_xpu.cc,这里面就调用了一个叫做xpu::resnet_unit_fusion的算子。受限于篇幅,大家有兴趣的话,可以自己去研究一下。
回顾昆仑芯与飞桨适配历程
到此为止,纯技术部分,或者说贴代码的部分就结束了。我们回顾一下,正是由于飞桨框架本身对于不同类型异构设备的灵活支持,以及昆仑芯底层软件栈对外提供的尽量简洁、清楚而又灵活的接口,再加上双方的共同努力来进行对接,才做到开场视频中,一行代码或者说只改一个字母就能搞定设备切换的功能。
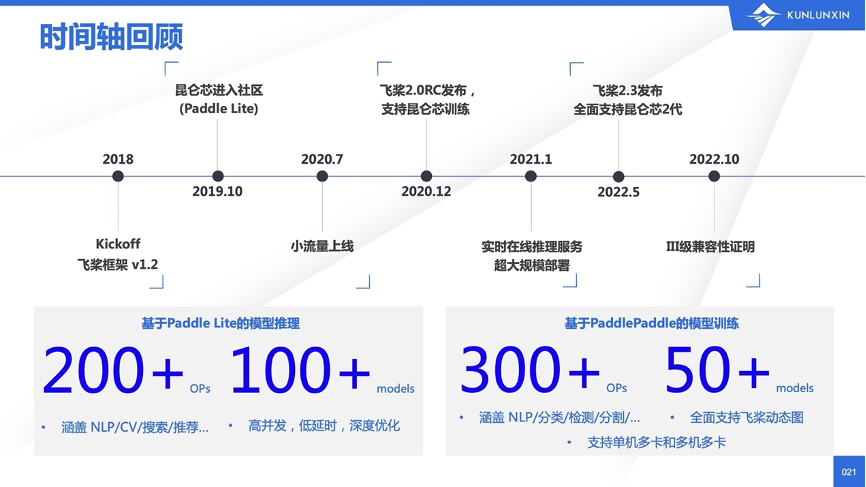
回顾过去,昆仑芯从2018年开始和飞桨进行对接,从推理开始一直到现在全方面的训练的支持,一共支持了300多个算子,以及在大规模数据下验证的50多个模型。
此外,对应的流水线和单侧也都已经建立,并且还在不断完善之中。我们还有200多个模型,在小数据下跑通了飞桨的TIPC认证的全流程。
需要特别强调,并不是我们这边发布了51个模型可以通过,昆仑芯就只能跑这有限的51个模型。目前飞桨的算子调用机制已经能够保证,如果一个算子在执行的设备上找不到,也就是说它缺实现,那么就会默认采用CPU算子进行计算。虽然速度可能慢一点,但通常情况下不会导致训练的失败。
当然,如果算子实在是太特殊的话,在CPU上都不能实现,训练可能还是会失败,但这种情况整体来说非常少见。
下面是昆仑芯适配飞桨模型的完整列表,继续请我的同事李琦来为大家介绍。
飞桨训练芯片适配技术负责人李琦

昆仑芯目前和飞桨已经适配了超过51个全量数据集的模型。这里的全量数据集,是指在标准的公开数据集上进行了完整的训练,并且最终的训练结果是符合模型对应的精度要求的。右侧的表格就是这51个模型列表,除了基础的CV类的图像分类、检测、分割和视频的模型之外,同样也支持字符识别的OCR模型,自然语言处理的NLP模型,以及推荐、语音和强化学习等模型,在模型数量和类型的覆盖度上都达到了飞桨适配认证的III级标准。
除了这51个全量数据集之外,昆仑芯还在额外的221个模型上跑过少量数据集的功能验证,也是可以成功运行的。这里所说的少量数据就是只跑功能,不做精度检测。同时,飞桨的官网上已经发布了关于昆仑芯的模型支持列表和安装说明文档,以及包括详细的训练示例和推理示例,大家如果对目前飞桨和昆仑芯的适配进展感兴趣,欢迎访问飞桨的官网来获取更多的详细信息。
https://www.paddlepaddle.org.cn/documentation/docs/zh/develop/guides/hardware_support/xpu_docs/paddle_2.0_xpu2_cn.html
昆仑芯科技资深架构师 侯珏

从整体上来说,昆仑芯和飞桨不仅仅是算子适配的简单合作关系,而是已经构建成了一系列完整的生态和系统性的解决方案。
除了飞桨框架以及周边的PaddleClas、PaddleDetection等套件,昆仑芯和飞桨还在更上层、更面向用户,而不仅仅是面向开发者的方面,有平台层次和解决方案层次的合作。比如百度全功能AI开发平台BML,以及对外以集成硬件形态发布的AI服务器,即飞桨一体机,都可以看到昆仑芯和飞桨成功合作的身影。
昆仑芯不但原生适配了飞桨,适配了BML平台,还自然能适配上层垂类的AI能力引擎。所以,从底层AI算力到上面的AI服务器、昆仑芯SDK、AI开发平台,面向最终用户以及面向最终客户等,在多个层面上都有一套端到端的AI计算系统的解决方案。
以上是分享的所有内容,希望能够对广大开发者、广大用户、广大客户提供有益的帮助,也希望昆仑芯和飞桨能够和大家一起成长。
昆仑芯公众号
扫码关注昆仑芯科技公众号




 昆仑芯科技公众号
昆仑芯科技公众号
 昆仑芯科技留言板
昆仑芯科技留言板