
扫码关注昆仑芯科技公众号
分享|昆仑芯×飞桨:实践探索与落地应用
芯见闻 发布于 2022-10-24 18:30
近日,来自飞桨与昆仑芯科技的两位专家带来了一场精彩的线上直播,从落地应用案例角度对昆仑芯与飞桨III级适配进行深度解读。
本篇以下内容整理于昆仑芯×飞桨系列直播第一期——昆仑芯科技研发总监罗航、飞桨高级产品经理王凯题为“昆仑芯×飞桨:实践探索与落地应用”直播分享。
本次分享分为四个方面:
AI芯片是产业发展的必然趋势

昆仑芯科技研发总监罗航
整个计算产业的周期可以粗略划分为四个阶段:
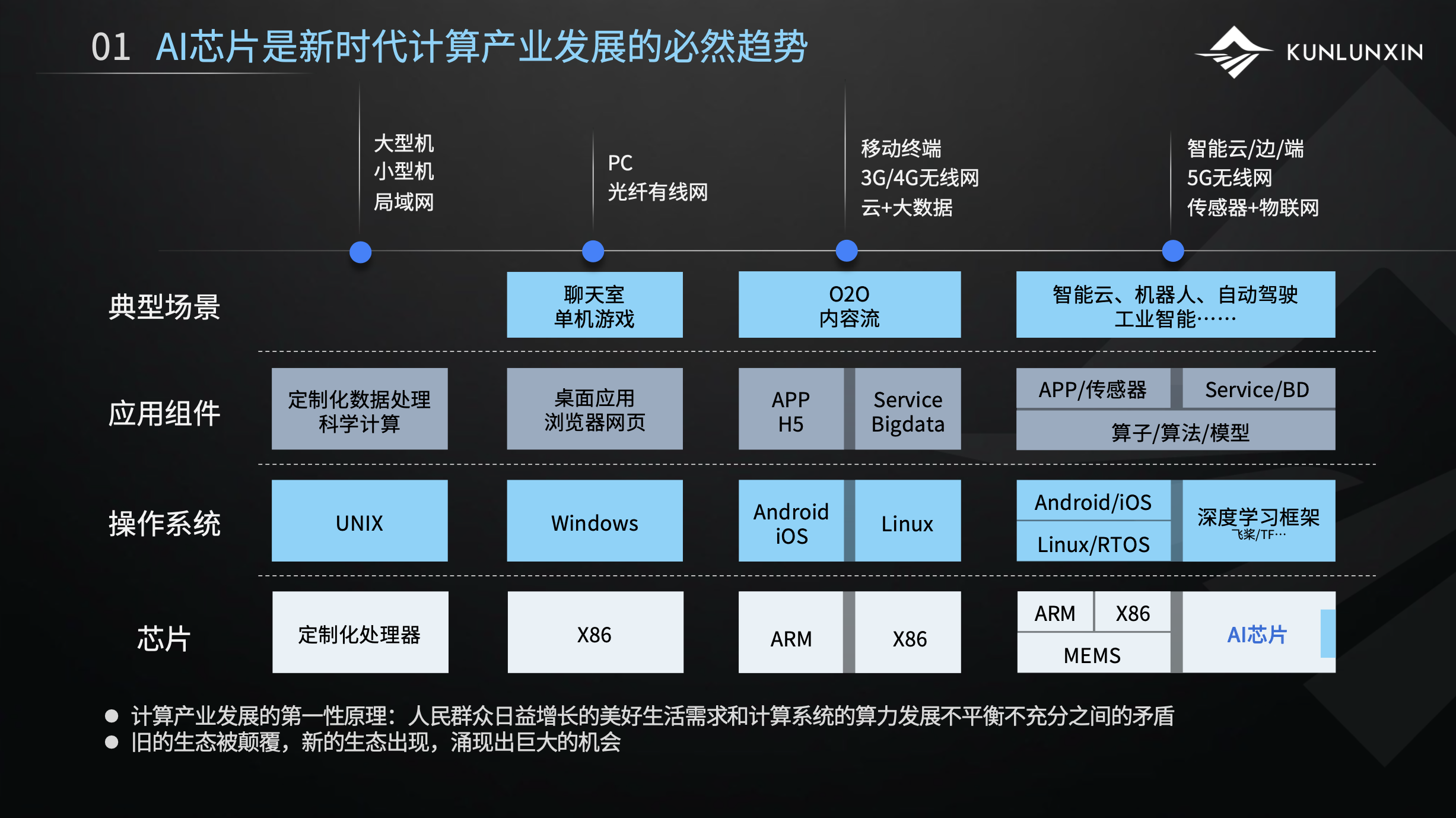
1.互联网上古时期。它是一个定制化的UNIX操作系统,主要群体是科学家,它的互联网形态,是一个很小规模的局域网形态。
2.PC互联网。这个时候才真正进入了普罗大众,我们才能感受到计算产业的魅力。它和上古形态有很大区别,它形成了一个x86 Windows强生态组合,有很多应用百花齐放。
3.移动互联网时代。这个产业形态的组织形式是基于4G、5G的移动互联网,相比上一个阶段,它的网络规模和通讯速度有一个质的飞跃,并且产业形态有一个很重要的变化,可以看到这张图中间出了一条线,这条线代表分化。它分化成了左边移动端的架构和右边中心端或叫云端的架构。为什么会有这样的分化?因为在移动互联网时代,原先x86和Windows的组合无法满足移动端低功耗的场景,所以分化催生出了ARM加Android和IOS的生态,形成了移动端和云端并存的形态。
4.AI时代。可以看到它的分化更复杂了。为什么会出现这样的分化?因为AI的蓬勃发展,导致数据量爆炸以及计算需求的爆发式增长,传统CPU通用计算提供的算力,已经远远不能满足AI时代的计算需求,所以催生出了多种计算架构,不同的计算架构处理各自擅长的数据需求,AI芯片应运而生。CPU、x86等多种计算架构的有机整合就叫异构计算。未来很有可能还会沿着这种分化趋势继续演变。
从这里可以看到,计算产业体系结构的演化很像生物的演化,都是从简单到复杂,比如生物演化是从单细胞到分化出各种器官,从而组成复杂精密的人体。我们借用“十九大”对社会主要矛盾的表述:人民群众对计算的需求,与计算系统的算力发展不平衡之间的矛盾,驱动着整个产业的迭代和发展。
每一次的迭代、分化,都会涌现出巨大的产业机会。
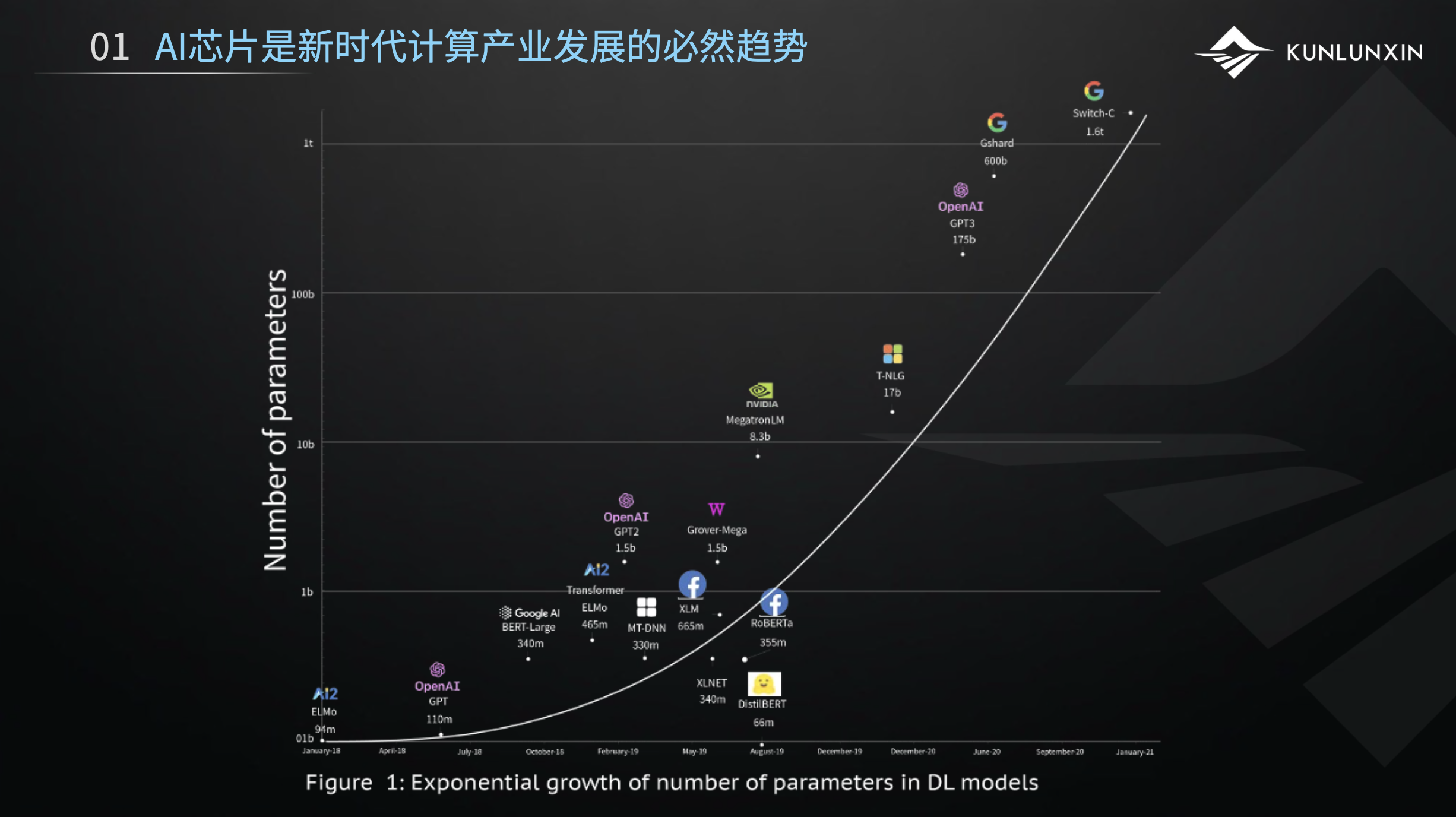
这张图表达的是一个客观事实:AI模型的规模呈指数型爆发式增长。模型在某种意义上等同于数据,模型越来越大代表数据量越来越大。模型简单来讲就是经验,相对于人是经验,相对于机器就是模型。图中有前段时间非常火的GPT3,这个模型的参数量达到了1750亿个,后来Google又发布了一个1.6万亿的超大模型。国内有很多机构也推出了大模型,比如百度的文心大模型,以及智源研究院的悟道大模型等。
大模型是正在发生的事实,也是一个很大的趋势。模型越来越大,对AI芯片及其算力的需求也来越大。上面这张图也从侧面佐证了计算产业等发展和分化的趋势。这也是AI芯片开始逐步产业化的特征所在。
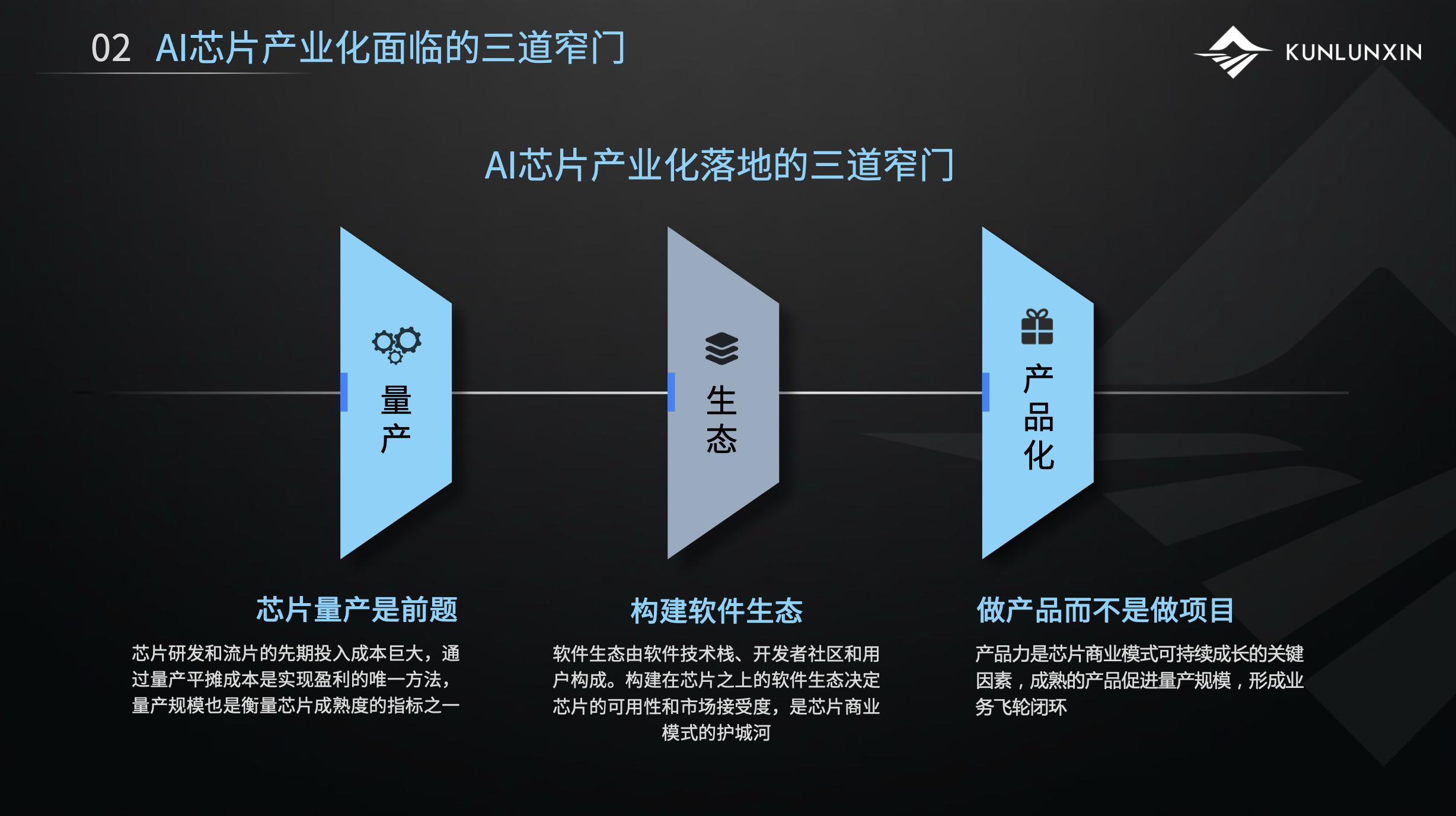
AI芯片产业化面临的三道窄门
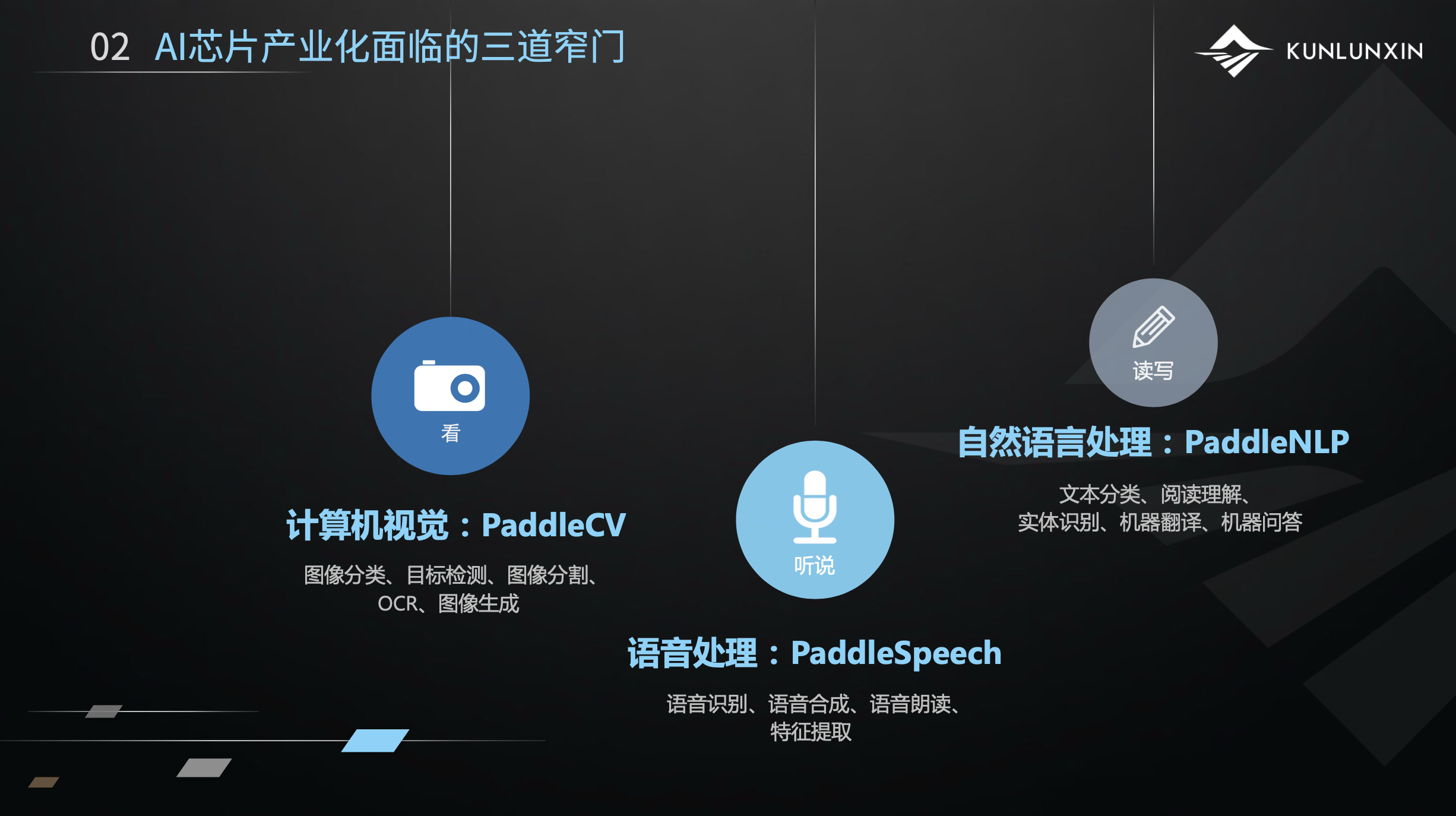
可以看到,AI软件生态可以抽象地划分为三大类:
以上三类场景,PaddlePaddle都有相应的很完善的模型库。计算机视觉类的叫PaddleCV,语音类的叫PaddleSpeech,自然语言处理类叫PaddleNLP。这三个模型库很好用,如果感兴趣,可以在PaddlePaddle的官网下载体验。[1]
接下来有请飞桨高级产品经理王凯为大家介绍飞桨在AI生态中的发展。
飞桨与昆仑芯携手建设AI产业生态

飞桨高级产品经理王凯
我是飞桨高级产品经理王凯,很高兴为大家分享飞桨与昆仑芯在AI产业生态上的建设成果。

昆仑芯与飞桨的合作由来已久。虽然图中显示2018年我们才开始合作,但实际早在飞桨成立之初,当时昆仑芯还在prototype阶段,双方的技术团队就已经有非常深入的合作交流。
随着双方产品的不断成长,我们的技术合作成果不断在百度厂内、厂外的业务上线落地。其中包括了2020年7月我们在厂内业务的小流量上线;2021年1月,我们共同实现了实时在线推理服务超大规模部署。
而就在上个月,飞桨与昆仑芯完成了III级适配认证,这是飞桨今年发出的第一个III级适配认证证书,也是飞桨硬件生态建设的一个里程碑。飞桨一直致力于与硬件伙伴共建软件生态,我们希望通过联合研发、资源共享、联合授权和培训赋能等各种手段,为硬件合作伙伴的AI软件生态贡献力量。所以今天在我们完成III级适配认证的基础上,我们跟昆仑芯联合举办系列直播课,向我们广大的开发者介绍我们的合作成果,我们也希望能够帮助更多AI产业的伙伴进行产业落地。
下面我将时间交还给罗航,邀请他继续给大家介绍我们的实践探索和应用案例。
昆仑芯和飞桨在实践探索和行业落地应用的案例
昆仑芯科技研发总监罗航
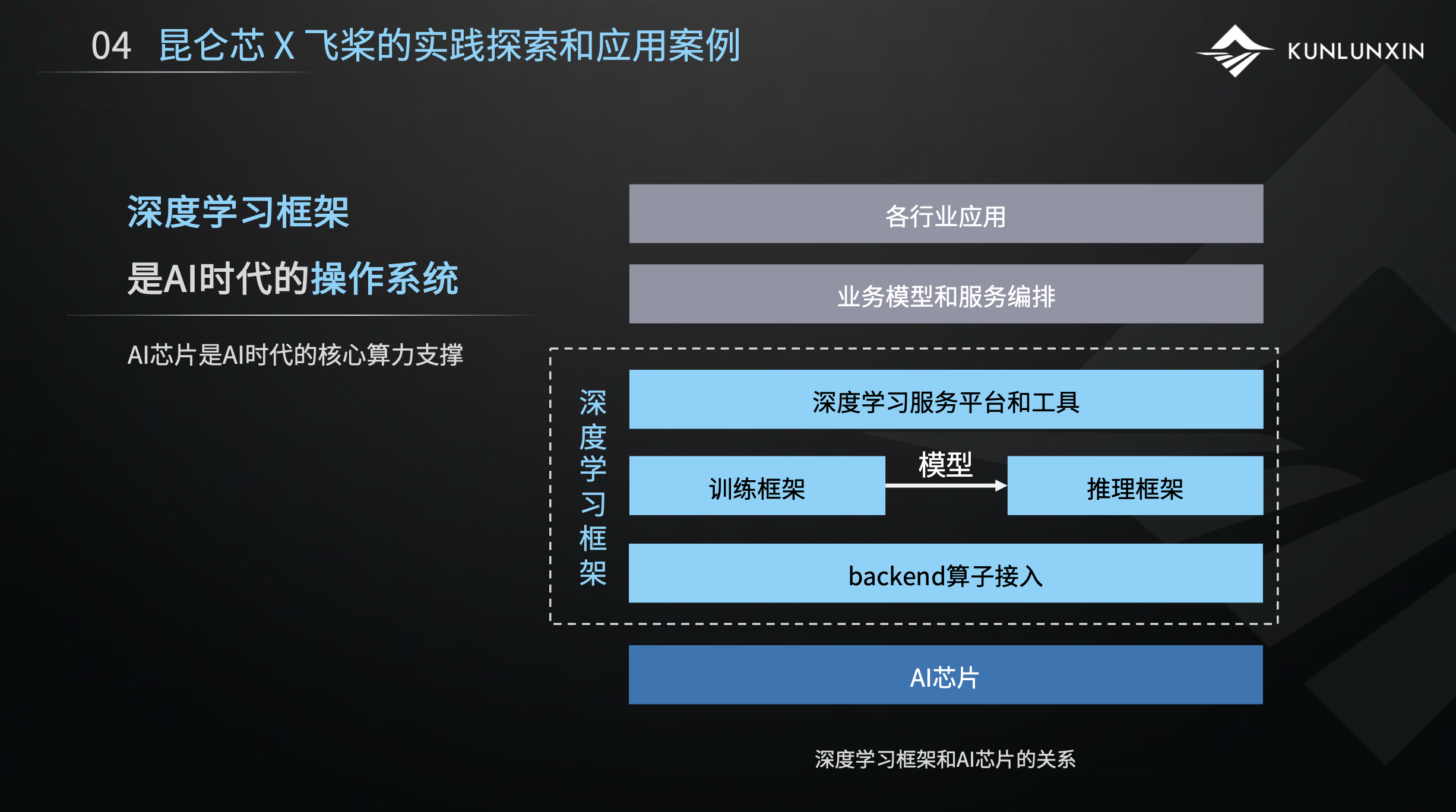
可能大家听过这种说法:深度学习框架是AI时代的操作系统。为什么?图中这个比较抽象的技术栈,从底层往上看,最下层是AI芯片的硬件支撑,芯片之上支撑着深度学习框架,框架之上又支撑了各种各样的应用和业务。
从关系来看,可以一一对照到CPU和操作系统,以及操作系统中的应用。比如操作系统也是对下接入不同的硬件,对上支撑不同的应用。深度学习框架是一样的,对下结合各种各样的AI芯片、异构的算力芯片,对上支撑了各种各样的算法应用。
可以说,深度学习框架和AI芯片,又是AI时代召唤出来的很重要的两个组件。所以,我们说深度学习框架是AI时代的操作系统,以及AI芯片是AI时代的核心算力支撑。
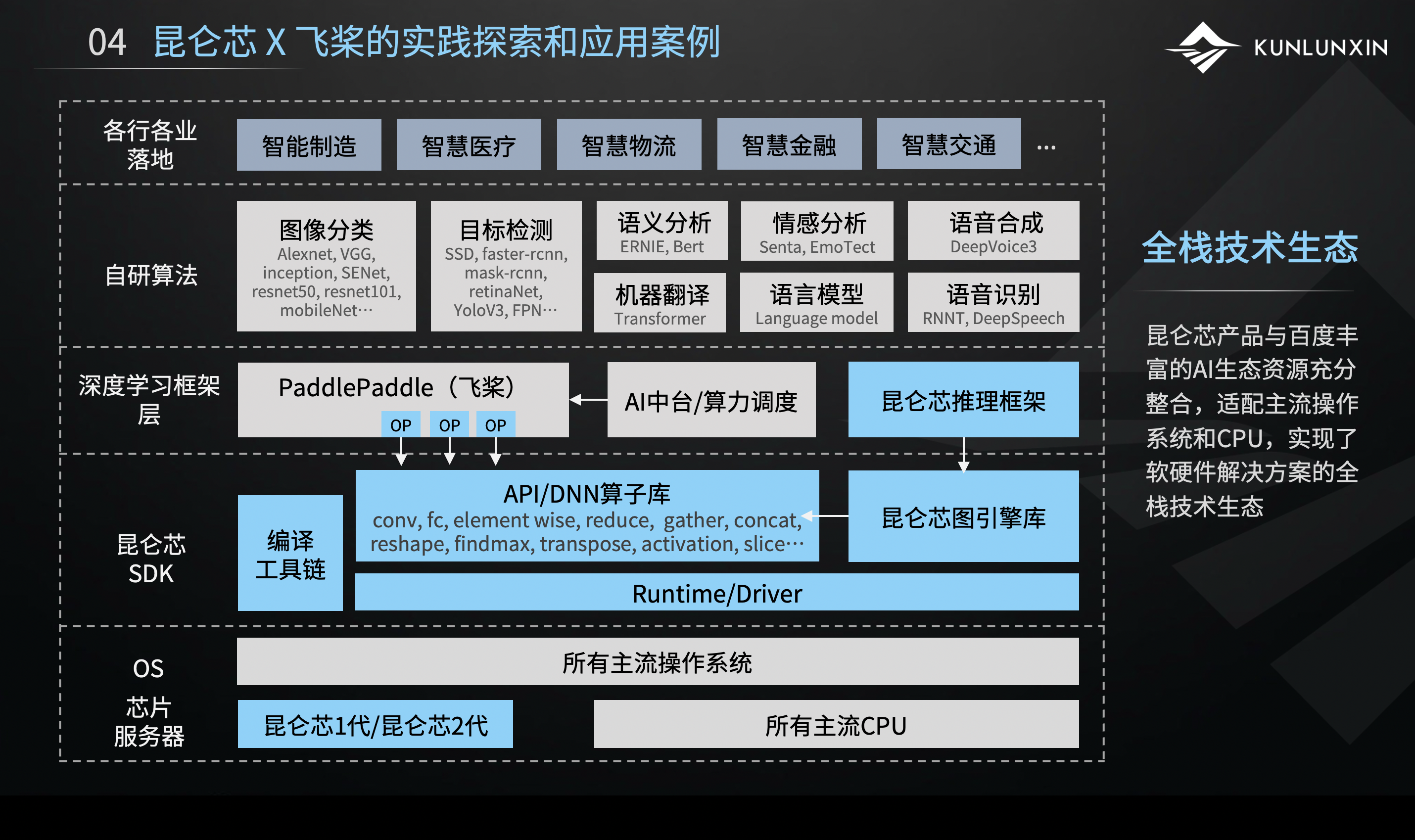
上图是细化版的技术栈图示,展示了飞桨PaddlePaddle和昆仑芯共同打造的技术生态,是一个很丰富的、全栈的技术生态。
简单来看,从底层硬件层,包括服务器芯片和操作系统,一直到上层应用层,这是一个全栈打透的技术生态。包括底层的服务器、中间的算子库以及深度学习框架。深度学习框架之上提供了很多算法,在算法的加持下,我们可以做很多的应用落地。
我们有一个很完整的全栈生态,飞桨一体机,其实就是全栈技术生态的物理标品,或者说是框架、芯片、算法和应用的一个集大成者。飞桨一体机集成了昆仑芯AI加速卡R200、版本较高的PaddlePaddle深度学习框架,并提供了单机两卡、四卡、八卡三款选择。
框架之上集成了飞桨BML企业版。BML是机器学习平台,客户可以从训练到推理全链路使用。开发平台之上,内置了至少100多个行业的模型应用,足以让客户拿到飞桨一体机之后实现开箱即用。

举个OCR场景的例子。基于飞桨一体机的集群,可以实现一些通用OCR场景。OCR的使用场景非常广泛,比如金融行业卡证票OCR模型套件识别的效果就非常好。
在飞桨一体机之上,可以搭载OCR服务引擎,引擎内包含了资源调度、虚拟化等集群纳管的能力。以及内置很多OCR场景的细分模型,包括文字识别、卡证识别、票据识别、表格识别等。此外,还集成了Paddle Serving的服务化框架,对上提供服务化接口。
这样的模型可以很方便地供客户PaaS去调用。因为很多买飞桨一体机,或OCR引擎服务的客户,有自己的PaaS。PaaS一般都需要一个服务化引擎,调用起来比较方便,而且耦合性也比较低。所以通过这种设计,可以实现对业务层足够的透明,PaaS平台以及其上的应用层移植到飞桨和昆仑芯的技术栈是非常容易的。
同理,基于飞桨一体机,我们可以做OCR的场景,也可以在上面换一些引擎。比如换成CV的引擎、NLP的引擎,也可以做一些其他的引擎。通过打造这样一个飞桨一体机,可以很方便的去做各种场景,为各种各样的行业客户提供服务。

大规模训练是很多客户非常关心的一个场景功能,特别是多机多卡的大规模训练。其实,飞桨PaddlePaddle和昆仑芯在大规模训练场景中,做了非常多的技术点创新和优化。
上图中可以看到,最底层是昆仑芯和CPU共同接入了飞桨平台,也就是一个异构平台接入。在飞桨内部分了几个模块,其中重点在于昆仑芯XPU架构。每一个昆仑芯XPU架构上,都有一个训练逻辑实体。多个训练逻辑实体通过CCIX或PCIE RDMA进行数据同步。通过数据同步,飞桨平台做了非常多的优化。
在这个同步的机制上,昆仑芯提供了XCCL高性能通信库,以保证多卡之间、多机之间通信的性能。
同时这里还实现了参数分级存储的创新。最底下SSD,可以通俗理解为硬盘,MEM可以理解为内存,片上HBM,通俗来讲,可以认为是昆仑芯上的显存。
这三级存储,分别存了不同类型的数据。比如说在训练的时候,在硬盘上存的是全量的参数数据。一些热点参数可以加载到内存中,提高访存效率。还有一些在片上直接运行的数据,就会加载到HBM,即昆仑芯的显存里,提高昆仑芯上的访存效率。通过参数分级的存储来管理,极大提升了整体架构的训练、访存的效率。
对于有大规模训练场景的客户,由于飞桨提供了大规模训练的DEMO,客户无需详细了解技术细节,直接下载即可方便地找到并运用应用型的代码。
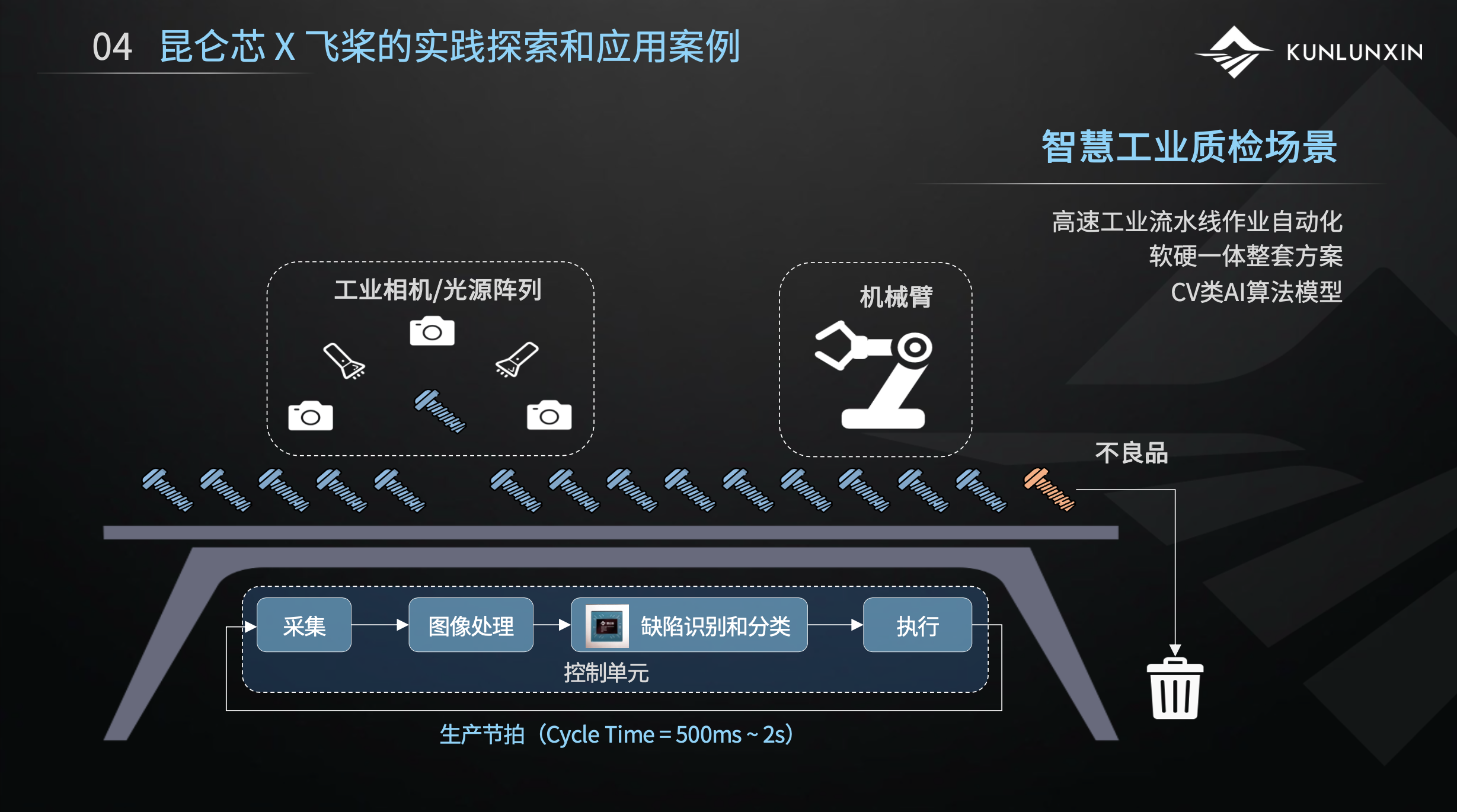
举一个工业质检的落地案例。这是一个流水线的示意图,产品经过流水线时,我们要去检测产品是不是合格、有没有缺陷。以往都是人工用肉眼去检测,拿起一个产品检查至少需要好几秒钟,特别费眼。
昆仑芯提供的方案是通过相机和光源阵列,从各个角度拍摄产品,得到图像之后,通过AI做图像处理和识别判断产品上有无缺陷,如果有缺陷就丢弃。该方案是全自动化的,无需人工干预,可以在一秒之内完成,极大提高了工业质检的效率。
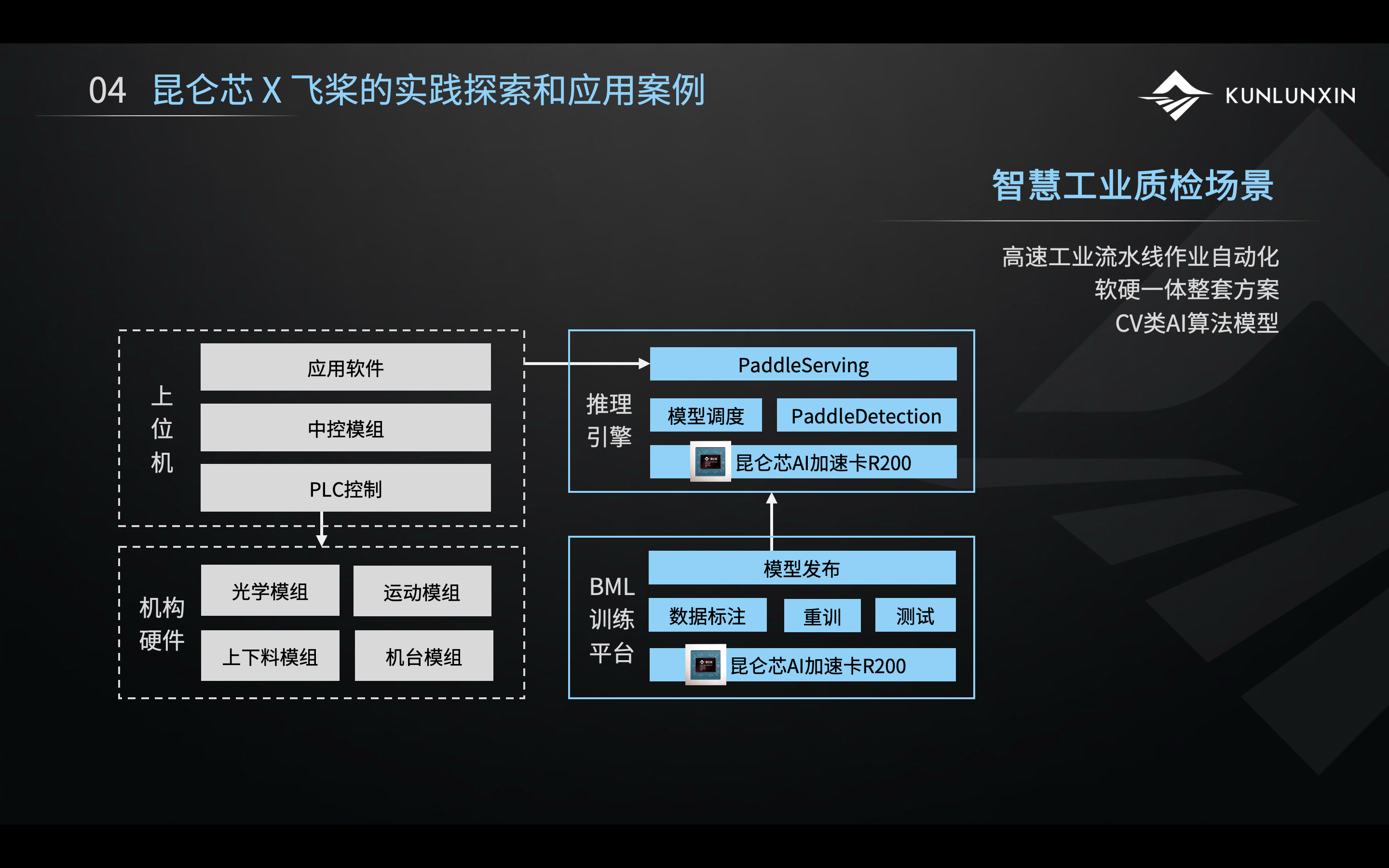
这是上述场景的细化架构图。左边两个灰色框,可以认为是客户的机器,右边是昆仑芯和飞桨提供的机器模块。这种设计的耦合度非常低。客户已有的东西,包括软件、运动模组以及控制模组等,均无需改变。客户在应用软件中,只需改变AI相关的引擎的调用。昆仑芯在这里提供的缺陷识别引擎基于PaddleDetection套件,由昆仑芯AI加速卡R200提供算力支撑。
对客户暴露的是一个通过Paddle Serving封装出来的服务化接口,与前文提到的OCR类似,都是提供服务化接口,可以很方便地调用,且耦合度非常低,对客户的代码也没有太多侵入。
基于推理引擎,客户可以把已训练好的模型通过推理引擎推起来,直接上产线。如果发现模型在产线上效果不好,需要调优、调精度,我们提供了由昆仑芯AI加速卡R200提供算力支撑的企业级BML训练平台,该平台上有一套数据标注的平台,产线工人可以很方便地使用这套工具,在生产线现场做图片标注。通过BML上一些简单的操作,可以基于现场的图片做重训,得到新的模型去做测试,测试后可以自动发布到产线上。
这一套平台是直接用在产线侧的,把模型的重训、测试以及发布,全流程打通,可以方便地在产线直接做高频的模型迭代,适应各个产线不同的产品以及有新产品上线之后可以快速训出适合的模型快速应用起来。
[1] https://www.paddlepaddle.org.cn/overview
昆仑芯公众号
扫码关注昆仑芯科技公众号





 昆仑芯科技公众号
昆仑芯科技公众号
 昆仑芯科技留言板
昆仑芯科技留言板