为智能计算而生的昆仑芯XPU架构
昆仑芯科技团队于2017年在Hot Chips上发布自研的、面向通用AI计算的芯片核心架构——昆仑芯XPU。
集十余年AI加速研发实践,昆仑芯XPU从AI落地的实际需求出发,按照复杂前沿的人工智能场景需求开展迭代,
致力为开发者提供通用、易用、高性能的算力来源。

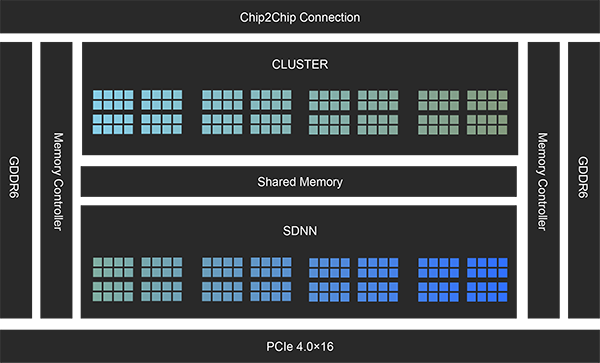
片间互联
有效提升大规模分布式训练中数据传输效率,减少通信延时。

GDDR6
具有较高能效比和性价比,是国内业界率先支持GDDR6的厂商之一。

Memory Controller
内存控制器是计算机系统内部控制内存并且负责内存与CPU之间数据交换的重要组成部分。

CLUSTER
自研高效SIMD指令集,支持标量和向量计算。

Shared Memory
片上共享内存,保证所有计算单元
高并发、低延时访问。

SDNN
自研核心张量计算单元,加速卷积和矩阵乘等计算。
Memory Controller
内存控制器是计算机系统内部控制内存并且负责内存与CPU之间数据交换的重要组成部分。
GDDR6
具有较高能效比和性价比,是国内业界率先支持GDDR6的厂商之一。

PCIe 4.0×16
支持PCIe第四代接口,可灵活搭配业界已上市AI服务器。
软件架构
AI算法和应用开发者在构建AI应用和业务的过程中,需要一套成熟的编程语言,以及完善的软件工具集来快速迭代开发任务。
昆仑芯SDK可以提供从底层驱动环境到上层模型转换等全栈的软件工具,包括如下内容:

产品研发路线图
目前,昆仑芯已成功推出两代通用AI计算处理器产品:昆仑芯1代AI芯片、昆仑芯2代AI芯片,及多款基于昆仑芯AI芯片的AI加速卡:K100、K200、 R100、R200系列,RG800以及AI加速器组R480-X8。新一代AI芯片、AI加速卡及更多产品正在研发中。
昆仑芯1代AI芯片

2019年
昆仑芯2代AI芯片

2021年
新一代AI芯片
AI加速卡及更多产品

未来









 昆仑芯科技公众号
昆仑芯科技公众号
 昆仑芯科技留言板
昆仑芯科技留言板